SoundNet: Learning Sound
Representations from Unlabeled Video
Yusuf Aytar *
Carl Vondrick *
Antonio Torralba
Massachusetts Institute of Technology
NIPS 2016
* contributed equally
Abstract
We learn rich natural sound representations by capitalizing on large amounts of
unlabeled sound data collected in the wild. We leverage the natural synchronization
between vision and sound to learn an acoustic representation using two-million
unlabeled videos. Unlabeled video has the advantage that it can be economically
acquired at massive scales, yet contains useful signals about natural sound. We
propose a student-teacher training procedure which transfers discriminative visual
knowledge from well established visual recognition models into the sound modality
using unlabeled video as a bridge. Our sound representation yields significant
performance improvements over the state-of-the-art results on standard benchmarks
for acoustic scene/object classification. Visualizations suggest some high-level
semantics automatically emerge in the sound network, even though it is trained
without ground truth labels.
Recognizing Objects and Scenes from Sound
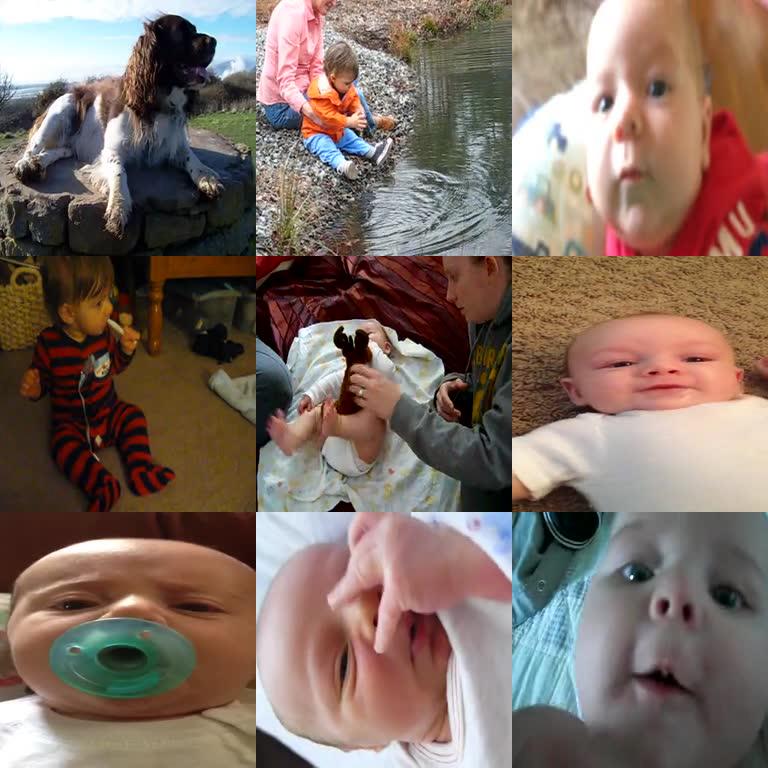
Given a video, our model recognizes objects and scenes from sound only. Click the videos below to hear some of the sounds and our model's predictions. Red are scene categories, and blue are objects. Turn on your speakers!
The images are shown only for visualization purpose, and not used in recognizing the sounds. We blurred the beginning of the video so you can try the task too and recognize it from sound alone.
Hearing the Hidden Representation
Although the network is trained without ground truth labels, it learns rich sound features. We visualize these features by finding sounds that maximally activate a particular hidden unit.
Click the images below to hear what sounds activate that unit. Turn on your speakers! You will hear the top 9 sounds that activate that unit.
Visualizing conv7
We visualize units in the deep layers in the network from conv7. Since we are deep in the network, sound detectors for high-level concepts can emerge automatically. Note the images are shown only for visualization purposes, and not used in analyzing the sounds.
Visualizing conv5
We can also visualize middle layers in the network. Interestingly, detectors for mid-level concepts automatically emerge in conv5.

Tapping-like
Thumping-like
Yelling-like
Voice-like
Swooshing-like
Chiming-like
Smacking-like
Laughing-like
Music Tune-like
Clicking-like
Visualizing conv1
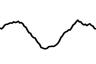
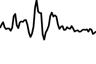
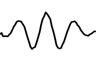
We visualize the first layer of the network by looking at the learned weights of conv1, which you can see below. The network operates on raw waveforms, so the filters are in the time-domain.
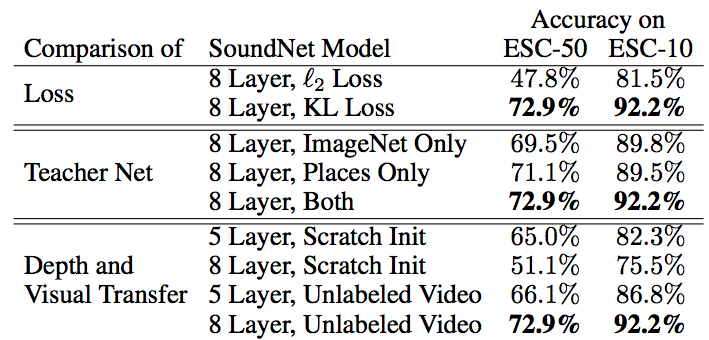
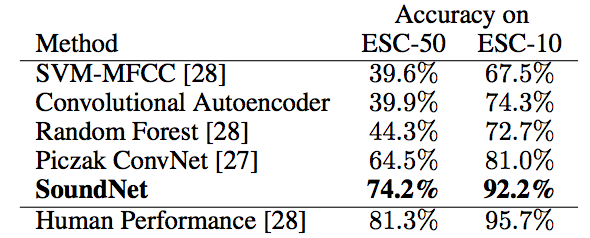
Performance
We experiment with SoundNet features on several tasks. They generally advance the state-of-the-art in environmental sound recognition by over 10%. By leveraging millions of unconstrained videos, we can learn better sound features.
 |
 |
| DCASE |
ESC 10 and ESC 50 |
We also analyzed the performance of different components of our system. Our experiments suggest that one may obtain better performance
simply by downloading more videos, creating deeper networks, and leveraging richer vision models.
Check out the paper for full details and more analysis.
Code & Trained Models

The code and models are available on Github and open source. It is implemented in Torch7. Using our pre-trained model, you can extract discriminative features for natural sound recognition. In our experiments, pool5 seems to work the best with a linear SVM.
Using the code is easy in Torch7:
sound = audio.load('file.mp3'):mul(2^-23):view(1,1,-1,1):cuda()
predictions = net:forward(sound)
SoundNet outputs two probability distributions of the categories that it recognizes for the input sounds. The first distribution are object categories, and the second distribution is scene categories. You can find the list of categories below:
Minor Note: SoundNet was trained with an older version of Places365. While Places365 will give good results, if you want to strictly reproduce our results, please use this VGG16 model that has 401 categories instead.
Data
We are releasing our Flickr video dataset for cross-modal recognition. Using our dataset, you can train large-scale sound recognition models. To train SoundNet, you need the raw MP3s and the image features. Optionally, you can download the original frames.
Videos from "Videos1" are part of the Yahoo
Flickr Creative Commons Dataset. Videos from "Videos2" are downloaded by
querying Flickr for common tags and English words. There should be no
overlap.
If you use this data in your research project, please cite the
Yahoo dataset and our paper.
We also release re-packaged versions of DCASE 2014 and ESC-50, which you can download here. These are the same as the original datasets, but converted to MP3 for easier processing. Please cite the DCASE and ESC-50 papers if you use this download.
Below are some sample scenes in this dataset:

Bibtex
If you find this project useful in your research, please cite:
Yusuf Aytar, Carl Vondrick, and Antonio Torralba. "Soundnet: Learning sound representations from unlabeled video." Advances in Neural Information Processing Systems. 2016.
@inproceedings{aytar2016soundnet,
title={Soundnet: Learning sound representations from unlabeled video},
author={Aytar, Yusuf and Vondrick, Carl and Torralba, Antonio},
booktitle={Advances in Neural Information Processing Systems},
year={2016}
}
Related Work
Cross-modal learning and perception is an exciting area of research! Check out some related work below:
Acknowledgements
We thank MIT TIG, especially Garrett Wollman, for helping store 26 TB of
video. We are grateful for the GPUs donated by NVidia. This work was supported by NSF grant
#1524817 to AT and the Google PhD fellowship to CV.